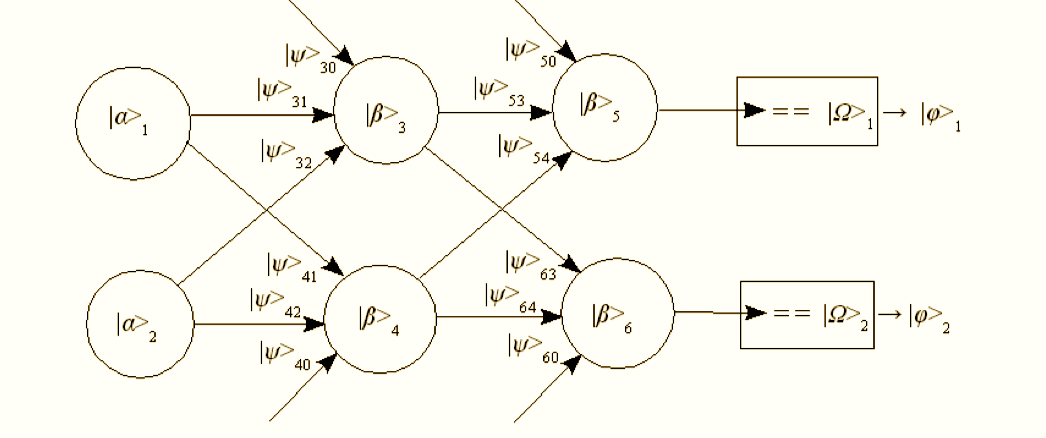
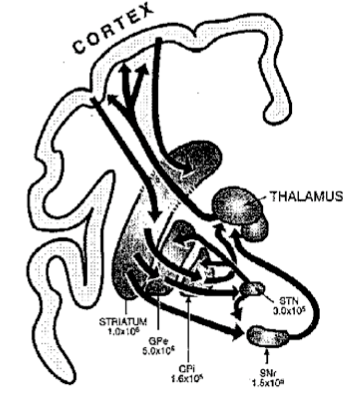
Recent work in deep learning networks has been largely driven by the capacity of modern computing systems to compute gradient descent over very large networks. We use gaming cards with GPUs that are great for parallel processing to perform the matrix multiplications and summations that are the primitive operations central to artificial neural network formalisms. Conceptually, another primary advance is the pre-training of networks as autocorrelators that helps with smoothing out later “fine tuning” training programs over other data. There are some additional contributions that are notable in impact and that reintroduce the rather old idea of recurrent neural networks, networks with outputs attached back to inputs that create resonant kinds of running states within the network. The original motivation of such architectures was to emulate the vast interconnectivity of real neural systems and to capture a more temporal appreciation of data where past states affect ongoing processing, rather than a pure feed-through architecture. Neural networks are already nonlinear systems, so adding recurrence just ups the complexity of trying to figure out how to train them. Treating them as black boxes and using evolutionary algorithms was fashionable for me in the 90s, though the computing capabilities just weren’t up for anything other than small systems, as I found out when chastised for overusing a Cray at Los Alamos.
Recent work in deep learning networks has been largely driven by the capacity of modern computing systems to compute gradient descent over very large networks. We use gaming cards with GPUs that are great for parallel processing to perform the matrix multiplications and summations that are the primitive operations central to artificial neural network formalisms. Conceptually, another primary advance is the pre-training of networks as autocorrelators that helps with smoothing out later “fine tuning” training programs over other data. There are some additional contributions that are notable in impact and that reintroduce the rather old idea of recurrent neural networks, networks with outputs attached back to inputs that create resonant kinds of running states within the network. The original motivation of such architectures was to emulate the vast interconnectivity of real neural systems and to capture a more temporal appreciation of data where past states affect ongoing processing, rather than a pure feed-through architecture. Neural networks are already nonlinear systems, so adding recurrence just ups the complexity of trying to figure out how to train them. Treating them as black boxes and using evolutionary algorithms was fashionable for me in the 90s, though the computing capabilities just weren’t up for anything other than small systems, as I found out when chastised for overusing a Cray at Los Alamos.
But does any of this have anything to do with real brain systems? Perhaps. Here’s Toker, et. al. “Consciousness is supported by near-critical slow cortical electrodynamics,” in Proceedings of the National Academy of Sciences (with the unenviable acronym PNAS). The researchers and clinicians studied the electrical activity of macaque and human brains in a wide variety of states: epileptics undergoing seizures, macaque monkeys sleeping, people on LSD, those under the effects of anesthesia, and people with disorders of consciousness.… Read the rest