 Sean Carroll of Caltech takes on the philosophy of science in his paper, Beyond Falsifiability: Normal Science in a Multiverse, as part of a larger conversation on modern theoretical physics and experimental methods. Carroll breaks down the problems of Popper’s falsification criterion and arrives at a more pedestrian Bayesian formulation for how to view science. Theories arise, theories get their priors amplified or deflated, that prior support changes due to—often for Carroll—coherence reasons with other theories and considerations and, in the best case, the posterior support improves with better experimental data.
Sean Carroll of Caltech takes on the philosophy of science in his paper, Beyond Falsifiability: Normal Science in a Multiverse, as part of a larger conversation on modern theoretical physics and experimental methods. Carroll breaks down the problems of Popper’s falsification criterion and arrives at a more pedestrian Bayesian formulation for how to view science. Theories arise, theories get their priors amplified or deflated, that prior support changes due to—often for Carroll—coherence reasons with other theories and considerations and, in the best case, the posterior support improves with better experimental data.
Continuing with the previous posts’ work on expanding Bayes via AIT considerations, the non-continuous changes to a group of scientific theories that arrive with new theories or data require some better model than just adjusting priors. How exactly does coherence play a part in theory formation? If we treat each theory as a binary string that encodes a Turing machine, then the best theory, inductively, is the shortest machine that accepts the data. But we know that there is no machine that can compute that shortest machine, so there needs to be an algorithm that searches through the state space to try to locate the minimal machine. Meanwhile, the data may be varying and the machine may need to incorporate other machines that help improve the coverage of the original machine or are driven by other factors, as Carroll points out:
We use our taste, lessons from experience, and what we know about the rest of physics to help guide us in hopefully productive directions.
The search algorithm is clearly not just brute force in examining every micro variation in the consequences of changing bits in the machine. Instead, large reusable blocks of subroutines get reparameterized or reused with variation.… Read the rest

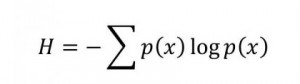 Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.
Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.


