 Since my time in the early 90s at Santa Fe Institute, I’ve been fascinated by the informational physics of complex systems. What are the requirements of an abstract system that is capable of complex behavior? How do our intuitions about complex behavior or form match up with mathematical approaches to describing complexity? For instance, we might consider a snowflake complex, but it is also regular in it’s structure, driven by an interaction between crystal growth and the surrounding air. The classic examples of coastlines and fractal self-symmetry also seem complex but are not capable of complex behavior.
Since my time in the early 90s at Santa Fe Institute, I’ve been fascinated by the informational physics of complex systems. What are the requirements of an abstract system that is capable of complex behavior? How do our intuitions about complex behavior or form match up with mathematical approaches to describing complexity? For instance, we might consider a snowflake complex, but it is also regular in it’s structure, driven by an interaction between crystal growth and the surrounding air. The classic examples of coastlines and fractal self-symmetry also seem complex but are not capable of complex behavior.
So what is a good way of thinking about complexity? There is actually a good range of ideas about how to characterize complexity. Seth Lloyd rounds up many of them, here. The intuition that drives many of them is that complexity seems to be associated with distributions of relationships and objects that are somehow juxtapositioned between a single state and a uniformly random set of states. Complex things, be they living organisms or computers running algorithms, should exist in a Goldilocks zone when each part is examined and those parts are somehow summed up to a single measure.
We can easily construct a complexity measure that captures some of these intuitions. Let’s look at three strings of characters:
x = aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
y = menlqphsfyjubaoitwzrvcgxdkbwohqyxplerz
z = the fox met the hare and the fox saw the hare
Now we would likely all agree that y and z are more complex than x, and I suspect most would agree that y looks like gibberish compared with z. Of course, y could be a sequence of weirdly coded measurements or something, or encrypted such that the message appears random.… Read the rest
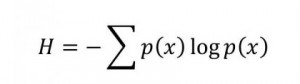 Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.
Research can flow into interesting little eddies that cohere into larger circulations that become transformative phase shifts. That happened to me this morning between a morning drive in the Northern California hills and departing for lunch at one of our favorite restaurants in Danville.