 Artificial Neural Networks (ANNs) were, from early on in their formulation as Threshold Logic Units (TLUs) or Perceptrons, mostly focused on non-sequential decision-making tasks. With the invention of back-propagation training methods, the application to static presentations of data became somewhat fixed as a methodology. During the 90s Support Vector Machines became the rage and then Random Forests and other ensemble approaches held significant mindshare. ANNs receded into the distance as a quaint, historical approach that was fairly computationally expensive and opaque when compared to the other methods.
Artificial Neural Networks (ANNs) were, from early on in their formulation as Threshold Logic Units (TLUs) or Perceptrons, mostly focused on non-sequential decision-making tasks. With the invention of back-propagation training methods, the application to static presentations of data became somewhat fixed as a methodology. During the 90s Support Vector Machines became the rage and then Random Forests and other ensemble approaches held significant mindshare. ANNs receded into the distance as a quaint, historical approach that was fairly computationally expensive and opaque when compared to the other methods.
But Deep Learning has brought the ANN back through a combination of improvements, both minor and major. The most important enhancements include pre-training of the networks as auto-encoders prior to pursuing error-based training using back-propagation or Contrastive Divergence with Gibbs Sampling. The critical other enhancement derives from Schmidhuber and others work in the 90s on managing temporal presentations to ANNs so the can effectively process sequences of signals. This latter development is critical for processing speech, written language, grammar, changes in video state, etc. Back-propagation without some form of recurrent network structure or memory management washes out the error signal that is needed for adjusting the weights of the networks. And it should be noted that increased compute fire-power using GPUs and custom chips has accelerated training performance enough that experimental cycles are within the range of doable.
Note that these are what might be called “computer science” issues rather than “brain science” issues. Researchers are drawing rough analogies between some observed properties of real neuronal systems (neurons fire and connect together) but then are pursuing a more abstract question as to how a very simple computational model of such neural networks can learn. And there are further analogies that start building up: learning is due to changes in the strength of neural connections, for instance, and neurons fire after suitable activation. Then there are cognitive properties of human minds that might be modeled, as well, which leads us to a consideration of working memory in building these models.
It is this latter consideration of working memory that is critical to holding stimuli presentations long enough that neural connections can process them and learn from them. Schmidhuber et. al.’s methodology (LSTM) is as ad hoc as most CS approaches in that it observes a limitation with a computational architecture and the algorithms that operate within that architecture and then tries to remedy the limitation by architectural variations. There tends to be a tinkering and tweaking that goes on in the gradual evolution of these kinds of systems until something starts working. Theory walks hand-in-hand with practice in applied science.
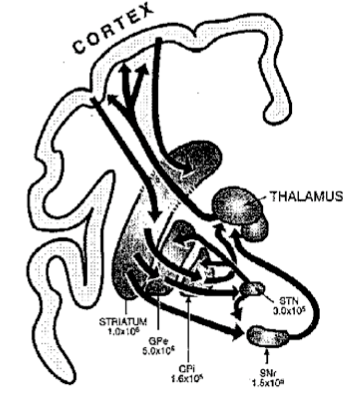
Given that, however, it should be noted that there are researchers who are attempting to create a more biologically-plausible architecture that solves some of the issues with working memory and training neural networks. For instance, Frank, Loughry, and O’Reilly at University of Colorado have been developing a computational model that emulates the circuits that connect the frontal cortex and the basal ganglia. The model uses an elaborate series of activating and inhibiting connections to provide maintenance of perceptual stimuli in working memory. The model shows excellent performance on specific temporal presentation tasks. In its attempt to preserve a degree of fidelity to known brain science, it does lose some of the simplicity that purely CS-driven architectures provide, but I think it has a better chance of helping overcome another vexing problem for ANNs. Specifically, the slow learning properties of ANNs have only scant resemblance to much human learning. We don’t require many, many presentations of a given stimulus in order to learn it; often, one presentation is sufficient. Reconciling the slow tuning of ANN models, even recurrent ones, with this property of human-like intelligence remains an open issue, and more biology may be the key.